チュートリアル
Oktaviaには多くのコンポーネントが含まれています:
- コマンドラインツール(インデックスジェネレータ、検索)
- プログラマ向けのカスタマイズ可能な部品
- JavaScriptライブラリ
このドキュメントでは、コマンドラインツールを使って検索エンジンを動かしていきます。
ダウンロード
OktaviaのツールとライブラリをGithubからダウンロードします。
Oktaviaのコマンドラインツールの実行にはnode.jsが必要です。0.8.21を使って動作することは確認しています。コマンドを実行する前にまずはnode.jsをインストールします。インデックスジェネレータはnode.jsの上で実行されます。 node.jsのウェブサイト には、さまざまなプラットフォームへのインストールの仕方が書かれています。
Oktaviaはシンプルなサンプルプログラム``httpstatus`` を提供しています。このプログラムはHTTPのステータスコードを確認するものです。 bin フォルダに格納されています。下記のように使用します:
$ bin/httpstatus 30
300: Multiple Choices
301: Moved Permanently
302: Found
303: See Other
304: Not Modified
305: Use Proxy
これを実行すると、”30”を含むステータスコードを返します。
Oktaviaは範囲検索以外の、Google方式の検索クエリー文法をサポートしています:
- すべての単語を含む: word1 word2
- 完全に一致する単語、フレーズ: "word1 word2"
- どちらかの単語を含む: word1 OR word2
- この単語を含まない: -word1
次のクエリーを実行すると、”40”を含むが、”not”を含まないステータスの行を返します:
$ ./httpstatus 40 -not
400: Bad Request
401: Unauthorized
402: Payment Required
403: Forbidden
407: Proxy Authentication Required
408: Request Timeout
409: Conflict
検索エンジンの裏では何が起こっているのか?
検索エンジンの内部では次のようなステップが実行されています:
- ソーステキストからインデックスファイルの作成
- ソースコンテンツを読み込む
- インデックスファイルを保存する
- コンテンツの検索と結果の表示
- インデックスファイルを読み込む
- ユーザのクエリーを受け取り、パースする
- 単語を検索する
- 検索結果のサマリーを作る
- 結果を表示する
httpstatus は一見シンプルなツールですが、この検索エンジンのすべてのステップを実行しています。
インデックスファイルを作成する
OktaviaはHTMLからインデックスを制するツール oktavia-mkindex を提供しています。それではPythonのドキュメントからインデックスを作成してみましょう。これを実行する前にMercurialをインストールする必要があります。
次のようにして、Pythonリポジトリをクローンしましょう:
$ hg clone http://hg.python.org/cpython
Pythonのソースコードをクローンしたら、次にHTMLドキュメントをビルドしてみましょう:
$ cd cpython/Doc
$ make html
(wait)
結果のHTMLファイルが cpython/Doc/build/html フォルダに生成されました。インデックスファイルを作成するには、次の情報が必要です。
- 入力ファイル: cpython/Doc/build/html
- ドキュメントルート: cpython/Doc/build/html
- モード: html
- 検索単位: file, h1 etc...
- フィルタ: HTMLタグ、ID、クラス
- キャッシュ密度(%)
入力ファイルは、個別のファイルを指定することもできますし、フォルダも指定できます。 oktavia-mkindex は入力ファイルを -i もしくは --input パラメータを使って指定しますが、複数渡すことができます。価値のある情報を含むページだけを追加してください。Pythonドキュメントにはインデックスページが含まれます。これらのページ自体は単なるリンク集なので、価値のある情報は含まれていません。
ドキュメントルートはブラウザのインデックスファイルにとって重要です。インデックスファイルは、このパスとの相対パスをドキュメントのパスとして保存しています。
Pythonのドキュメントのフォルダの cpython/Doc/build/html には library/os.html というファイルがあります。次の表はドキュメントルートのオプションの設定のサンプルです:
| ドキュメントルート | 結果のパス |
|---|---|
| cpython/Doc/build/html | /library/os.html |
| cpython/Doc/build/html/library | /os.html |
-r もしくは --root オプションを使ってドキュメントルートを設定します。
現在のバージョンのOktaviaは、HTMLモードのみをサポートしています。 -m html を指定してください。
検索単位は、情報の粒度を指定します。もし検索単位として file が指定された場合には、集計時に同じページ内に見つけた単語を一つにまとめます。もし h1 が指定された場合には、この h1 で区切られたグループで結果が集計されます。 oktavia-mkindex に集計単位を設定するには -u もしくは --unit オプションを指定してください。
フィルタは検索結果からノイズを除去する上で重要です。HTMLファイルには、コンテンツ以外にもヘッダー、サイドバー、フッターなどの共通要素が含まれています。Pythonドキュメントは <div class="body"> タグが含まれています。このタグの外側の内容は、HTMLテンプレートによって生成されたコンテンツです。これらの自動生成されたコンテンツは検索結果画面に表示させないべきです。 oktavia-mkindex は、オプションとして -f .body``もしくは ``--filter .body が設定されると、これらの余計な情報を無視します。
キャッシュ密度は、出力されるインデックスファイルの大きさとパフォーマンスに影響を与えます。デフォルト値は “5” (%)です。キャッシュ密度とキャッシュのサイズは正比例し、検索結果のレスポンスとは反比例します。PythonドキュメントはUTF-16にすると10MB(JavaScriptが使うテキストエンコーディング)のテキストがありますが、”5”を設定するとキャッシュのサイズは4MBにもなります。
もしトータルのファイルサイズが10MBを超えているが、検索機能は提供したい場合には、1か2、あるいはそれ以下の数値を設定してください。25のような大きな数値を設定すると、かつてないスピードを体験することができます。
次のコマンドを実行すると、インデックスファイルを生成することができます:
$ bin/oktavia-mkindex -i cpython/Doc/build/html/library -i cpython/Doc/build/html/c-api
-i cpython/Doc/build/html/reference -i cpython/Doc/build/html/tutorial
-r cpython/Doc/build/html -m html -u h2 -f .body -c 5
試しで使ったコンピュータでは20秒ほどでインデックスができあがりました。
cpython/Doc/build/html/search/searchindex.js というパスに検索のインデックスファイルが作成されました。これには、言語リファレンス、ライブラリリファレンス、C-API、Pythonチュートリアルに含まれる情報を含んでいます。
今作ったインデックスファイルの中の単語を検索
Oktaviaは検索コマンドの oktavia-search を提供しています。このコマンドの最初のパラメータは検索インデックスのファイルパスです。残りのパラメータは検索ワードです。
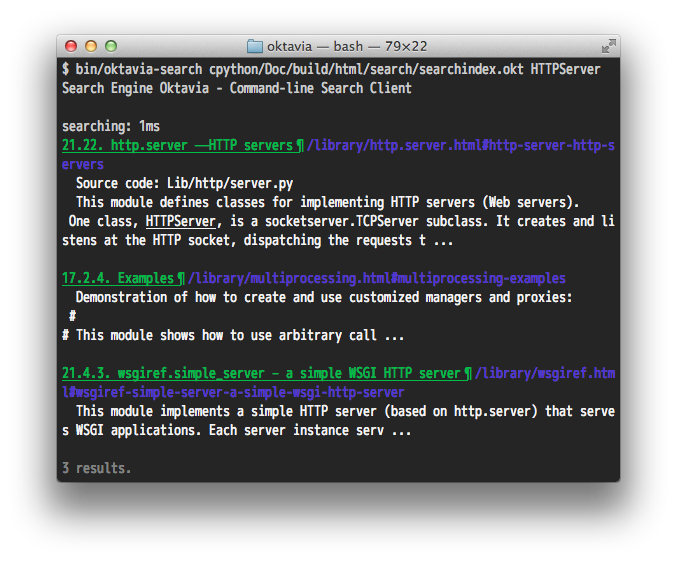
Tweet